Сотни систем на основе искусственного интеллекта были созданы для борьбы с КОВИД. Ни одна из них не помогла
Когда КОВИД-19 поразил Европу и Америку, больницы были ввергнуты в кризис здравоохранения. Но на тот момент уже были данные, поступающие из Китая, который на четыре месяца опередил пандемию. Если бы алгоритмы машинного обучения можно было обучить на этих данных, чтобы помочь врачам понять, что они видят, и принять решение, это могло бы спасти жизни.
Этого не произошло, но не из-за отсутствия усилий. Исследовательские группы по всему миру начали разрабатывать программное обеспечение, которое, по мнению многих, позволит больницам быстрее диагностировать или сортировать пациентов, оказывая столь необходимую поддержку на передовой. Но это только теоретически.
В итоге были разработаны многие сотни прогностических инструментов. Ни один из них не принес реальной пользы, а некоторые оказались потенциально вредными.
Таковы выводы многочисленных исследований, опубликованных за последние несколько месяцев. В июне Институт Тьюринга, британский национальный центр науки о данных и искусственном интеллекте, опубликовал отчет, в котором подвел итог обсуждений на серии семинаров, проведенных в конце 2020 года. Общий вывод заключался в том, что инструменты искусственного интеллекта (artificial intelligence, AI) оказали незначительное влияние на борьбу с ковидом, если вообще оказали.
Они не подходят для клинического использования
Этот вывод повторяет результаты двух крупных исследований, в которых оценивались сотни инструментов прогнозирования, разработанных в прошлом году. В обзоре, опубликованном в British Medical Journal, который до сих пор обновляется по мере появления новых данных и проверки существующих инструментов, ученые рассмотрели 232 алгоритма для диагностики пациентов или прогнозирования того, насколько сильно больные могут заболеть. Они обнаружили, что ни один из них не подходит для клинического использования. Только два были выделены как достаточно перспективные для дальнейшего тестирования.
Это исследование подкрепляется другим большим обзором, опубликованным в журнале Nature Machine Intelligence. Эта группа исследователей сосредоточилась на моделях глубокого обучения для диагностики КОВИД и прогнозирования риска для пациентов на основе медицинских изображений, таких как рентгеновские снимки грудной клетки и компьютерная томография (КТ). Они изучили 415 опубликованных инструментов и пришли к выводу, что ни один из них не подходит для клинического использования.
Обе группы обнаружили, что разработчики повторяли одни и те же основные ошибки в том, как они обучали или тестировали свои инструменты. Неверные предположения о данных часто означали, что обученные модели не работали так, как было заявлено.
Авторы обзоров по-прежнему считают, что AI способен помочь. Но они обеспокоены тем, что при неправильном построении моделей они могут нанести вред, поскольку могут пропустить диагноз или недооценить риск для уязвимых пациентов.
Нереалистичные ожидания способствуют использованию этих инструментов до того, как они будут готовы. Некоторые из рассмотренных в упомянутых исследованиях алгоритмов уже используются в больницах, а некоторые продвигаются на рынок частными разработчиками. Если и есть положительный момент, то он заключается в том, что пандемия дала понять многим исследователям, что необходимо изменить подход к созданию AI-инструментов.
Что пошло не так?
Многие из выявленных проблем связаны с низким качеством данных, которые исследователи использовали для разработки своих систем. Информация о пациентах с КОВИД, включая медицинские снимки, собиралась и распространялась в разгар глобальной пандемии, зачастую врачами, которые пытались лечить этих пациентов. Разработчики хотели помочь быстро, и это были единственные общедоступные наборы данных. Но это означало, что многие инструменты были созданы с использованием неправильно маркированных данных или данных из неизвестных источников.
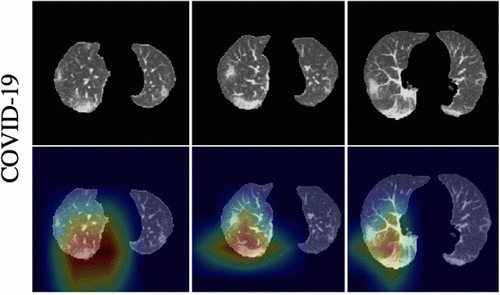
Такие наборы данных собирались из нескольких источников и могли содержать дубликаты. Это означает, что некоторые инструменты тестируются на тех же данных, на которых они были обучены, что делает их более точными, чем они есть на самом деле. Некоторые наборы данных содержали данные с неуказанным происхождением и это может означать, что исследователи упускают важные особенности, которые искажают процесс обучения их моделей. Многие невольно использовали набор данных, содержащий снимки грудной клетки детей, которые не болели КОВИД, в качестве примера того, как выглядят случаи, не связанные с этим заболеванием. Но в результате AI научился определять детей, а не КОВИД.
Ученые из Кембриджа обучили свою собственную модель, используя набор данных, в котором были представлены снимки, сделанные в положении пациента лежа и стоя. Поскольку пациенты, которых сканировали лежа, с большей вероятностью были серьезно больны, AI ошибочно научился предсказывать риск серьезного ковидного заболевания по положению человека.
В других случаях было обнаружено, что некоторые AI-системы улавливают шрифт текста, который определенные больницы использовали для маркировки сканов. В результате шрифты больниц с более серьезной нагрузкой стали предикторами риска КОВИД в таких системах.
Подобные ошибки кажутся очевидными в ретроспективе. Их также можно исправить путем корректировки моделей, если исследователи знают о них. Можно признать недостатки и выпустить менее точную, но и менее вводящую в заблуждение модель. Но многие инструменты были разработаны либо исследователями AI, которым не хватало медицинского опыта, чтобы заметить недостатки в данных, либо медицинскими исследователями, которым не хватало математических навыков, чтобы компенсировать эти недостатки.
Более тонкая проблема, на которую обращают внимание авторы публикации в Nature Machine Intelligence, - это предвзятость, возникающая в момент маркировки набора данных. Например, многие медицинские снимки были помечены в соответствии с тем, утверждали ли радиологи, которые их создавали, что они отражают КОВИД. Но это встраивает любые предубеждения конкретного врача в базовый набор данных. Было бы гораздо лучше помечать медицинские снимки результатами ПЦР-теста, а не мнением одного врача. Но в загруженных больницах не всегда есть время для статистических тонкостей.
Сегодня неясно, какие из вновь разработанных AI-систем используются и как. Иногда больницы заявляют, что они используют тот или иной инструмент только в исследовательских целях, что затрудняет оценку того, насколько врачи полагаются на них. До сих пор в этой сфере много секретности. Некоторые больницы даже подписывают соглашения о неразглашении с поставщиками медицинского AI.
Как это исправить?
Здесь могло бы помочь улучшение данных, но во время кризиса это большая проблема. Гораздо важнее максимально использовать имеющиеся массивы данных. Самым простым шагом было бы расширение сотрудничества групп разработчиков с врачами. Кроме того, они должны также делиться своими моделями и раскрывать информацию о том, как они были обучены, чтобы другие могли проверить их и построить на их основе свое решение. Это две вещи, которые можно бы сделать уже сегодня. И они решили бы, возможно, 50% проблем, которые были выявлены в исследованиях. Получение данных также было бы проще, если бы форматы были стандартизированы.

Еще одна проблема заключается в том, что большинство разработчиков поспешили создать собственные модели, вместо того чтобы работать вместе или совершенствовать существующие. В результате коллективные усилия по всему миру привели к созданию сотен посредственных инструментов, а не горстки правильно подготовленных и протестированных.
В некотором смысле это старая проблема научных исследований. У академических ученых мало карьерных стимулов делиться работой или подтверждать существующие результаты. Нет вознаграждения за прохождение "последней мили", которая ведет технологию от программного кода к постели больного.
Для решения этой проблемы Всемирная организация здравоохранения рассматривает возможность заключения чрезвычайного договора об обмене данными, который будет действовать во время международных кризисов в области здравоохранения. Это позволит исследователям легче перемещать данные через границы.
Такие инициативы звучат несколько расплывчато, а призывы к переменам всегда имеют оттенок желания. Это вяло обсуждается уже давно, но КОВИД вернул многие из этих вопросов на повестку дня.
По материалам The Alan Turing Institute, British Medical Journal, MIT Technology Review, Nature Machine Intelligence, Wired.

