5 подходов к устранению предвзятости при использовании искусственного интеллекта в здравоохранении
Исторически сложилось так, что медицинские данные были ориентированы на белых мужчин, и в эпоху искусственного интеллекта (artificial intelligence, AI) это представляет собой проблему для обучения алгоритмов, чтобы они выдавали результаты, репрезентативные для всего этнического и гендерного спектра. Cуществующая ситуация неизбежно приводит к "алгоритмической предвзятости" в здравоохранении. Последний термин исследователи определяют как случаи, когда применение алгоритма не только не учитывает неравенство, но и может усугубить его в системе здравоохранения.
Действительно, ученые уже обнаружили, что присущая данным необъективность может усиливать неравенство в здравоохранении среди расовых меньшинств. Сегодня важно повысить осведомленность об этом аспекте AI-алгоритмов, не менее важно знать о мерах, которые можно предпринять для устранения, а не избежания предвзятости, поскольку AI все больше становятся неотъемлемой частью здравоохранения.
Избавление от предвзятости в AI в здравоохранении - непростая задача, поскольку алгоритмическая предвзятость может быть внесена в любой момент цикла разработки программного обеспечения. Помимо традиционно предвзятых данных о здоровье, предвзятость может быть непреднамеренно внесена людьми, разрабатывающими алгоритмы, или способом отбора и измерения характеристик.
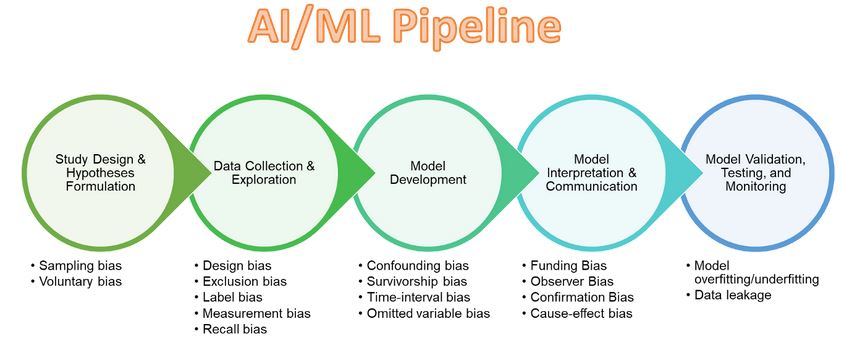
Что же можно предпринять, чтобы сделать применение А.И. в здравоохранении более справедливым? Вот 5 перспективных способов, которые обсуждают исследователи.
1. Непрерывная оценка
Американские ученые из Стэнфордского университета в недавнем отчете подчеркнули, что проблемы, которые приводят к предвзятости и неравенству в биомедицинских AI-программах, тесно связаны со сбором данных и оценкой алгоритмов. Для обеспечения надежного и корректного использования AI в здравоохранении они рекомендуют проводить регулярную оценку и мониторинг этих инструментов, а также собирать более разнообразные данные.
Например, они предлагают разработчикам AI-инструментов использовать существующие статистические тесты, позволяющие определить, значительно ли отличаются данные, использованные для обучения алгоритма, от фактических данных, с которыми они сталкиваются в реальных условиях. Это может указывать на смещения, связанные с обучающими данными, и разработчики могут соответствующим образом адаптироваться.
2. Создание стратегии устранения предвзятости, которая содержит портфель технических, операционных и организационных действий
Техническая стратегия включает инструменты, которые помогут определить потенциальные источники предвзятости и выявить черты в данных, влияющие на точность модели. Операционные стратегии включают улучшение процессов сбора данных с помощью внутренних "красных команд" и сторонних аудиторов. Практические методы можно найти, например, в исследовании Google AI о непредвзятости.
Организационная стратегия включает создание рабочего места, где метрики и процессы представлены прозрачным образом.
3. Использование алгоритмической "гигиены"
Когда дело доходит до сбора данных рекомендуется использовать эффективную "алгоритмическую гигиену" как одну из лучших практик для предотвращения предвзятости в AI. Это включает в себя понимание различных причин предвзятости и обеспечение максимально возможной репрезентативности данных, используемых для обучения. Необходимо изучить набор данных для обучения на предмет того, является ли он репрезентативным и достаточно большим, чтобы избежать распространенных ошибок, таких как смещение выборки.

Устранение предвзятости - это междисциплинарная стратегия, в которой участвуют специалисты по этике, социологи и эксперты, которые лучше всего понимают нюансы каждой прикладной области в процессе. Поэтому разработчики должны стремиться привлекать таких экспертов к своим проектам в области AI.
Ни один набор данных не может представлять всю совокупность вариантов. Поэтому важно заранее определить целевое применение и аудиторию, а затем адаптировать обучающие данные к этой цели.
4. Применение методов очистки от предвзятости
Консенсус о подходе к измерению или даже определению непредвзятости еще не достигнут, но меры для повышения его уровня в AI-прогнозах уже принимаются. Для этого разработчики применяют методы размывания, которые помогают уменьшить или устранить различия между группами или отдельными людьми по чувствительным признакам. Чтобы помочь разработчикам адаптировать существующие методы в своей работе, IBM создала инструментарий AI Fairness 360 с открытым исходным кодом. В 2021 году разработчики компании применили этот инструментарий в реальных сценариях, чтобы успешно учесть и уменьшить предвзятость при распределении ресурсов для женщин с послеродовой депрессией.
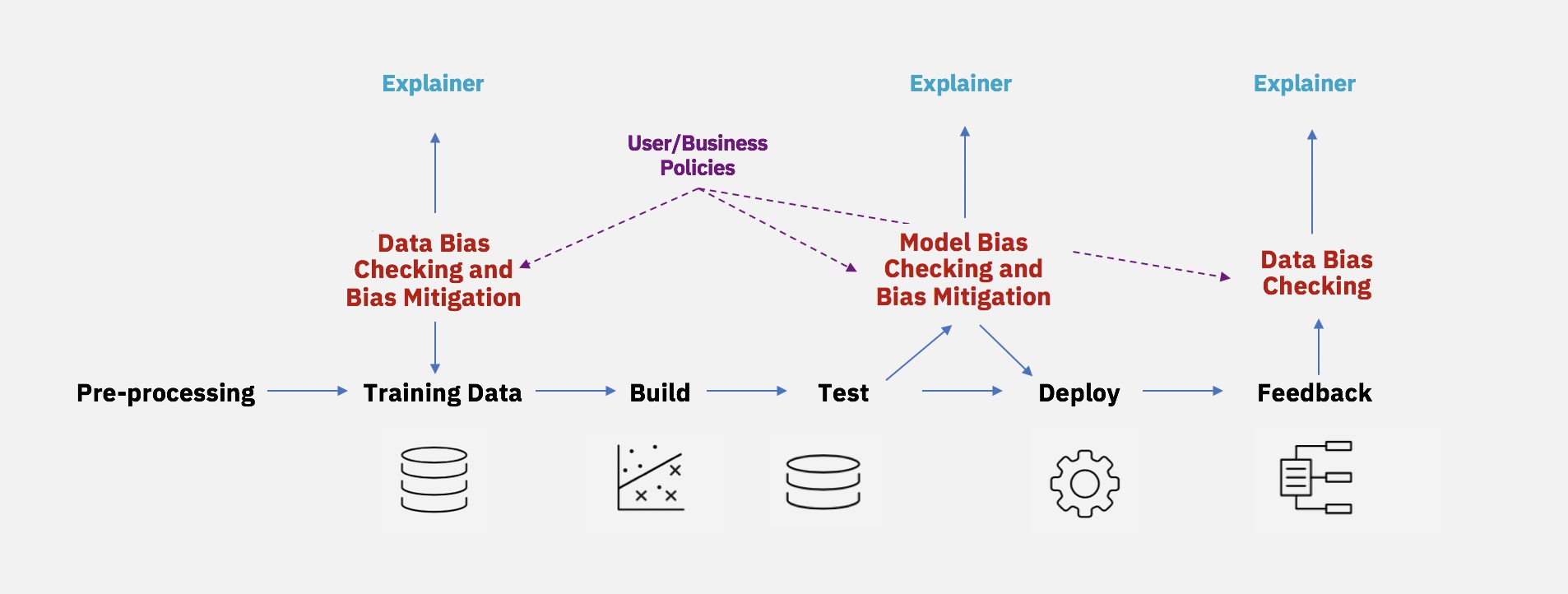
Этот инструмент позволяет тестировать смещения в моделях и наборах данных с помощью полного набора метрик. Кроме того, он обеспечивает смягчение влияния предубеждений с помощью 12 готовых алгоритмов, таких как Learning Fair Representations, Reject Option Classification, Disparate Impact Remover.
Однако алгоритмы AI Fairness 360 по обнаружению и устранению предвзятости предназначены для решения задач бинарной классификации, поэтому их необходимо расширить на многоклассовые и регрессионные задачи, если решаемая проблема более сложная.
5. Обеспечение прозрачности, конфиденциальности и нормативного надзора

Еще одним важнейшим фактором обеспечения непредвзятости при принятии решений с помощью AI является прозрачность. Это может выражаться в перекрестной проверке решений алгоритма человеком и наоборот. Для обеспечения такой прозрачности необходимо наличие сопутствующей вспомогательной инфраструктуры. Она включает в себя соответствующие технические, нормативные, экономические и другие инфраструктуры для предоставления необходимых больших и разнообразных данных для прозрачного обучения алгоритмов.
Производительность алгоритмов меняется по мере их применения с разными данными, разными настройками и разными взаимодействиями между человеком и компьютером. Эти факторы могут превратить AI в инструмент, который наносит непреднамеренный вред, поэтому эти алгоритмы должны постоянно оцениваться для устранения неотъемлемого и системного неравенства, которое существует в системе здравоохранения.
Надежного метода пока нет
Хотя существует множество потенциальных подходов к устранению предвзятости в AI, ни один из них не является надежным. Технически можно сделать непредвзятую систему. AI-система может быть настолько хороша, насколько качественны ее входные данные. Если вы сможете очистить набор обучающих данных от сознательных и бессознательных предположений о расе, поле или других идеологических концепциях, вы сможете построить AI-систему, которая будет принимать непредвзятые решения на основе данных.
Однако в реальном мире мы не ожидаем, что AI в ближайшее время станет полностью непредвзятым.
Технология AI движется в сторону большей интеграции всех аспектов жизни. По мере того, как это происходит, вероятность возникновения предвзятости возрастает в результате объединения сложных систем, но, как это ни парадоксально, ее не так легко выявить и предотвратить.
Однако это не означает, что разработчики не должны стремиться к устранению предвзятости в AI, поскольку без этого внедрение AI-систем в реальную практику будет затруднено. Необходимо признать, что алгоритмы могут принести как большую пользу, так и вред, и поэтому требуют изучения.
Таким образом, подобно тому, как мы контролируем и оцениваем лекарства и медицинские приборы, мы должны контролировать и оценивать AI не только с точки зрения их эффективности, но и на основе отсутствия предвзятости.
По материалам Healthcare IT News, Medical Futurist, Provider Tech, PubMed Central, Stanford University, AI Multiple.

