Опыт первой регистрации СППВР в России
Для экспертов уже давно стало аксиомой то, что системы, основанные на искусственном интеллекте и машинном обучении, облегчающие принятие решений в области здравоохранения — самые многообещающие инструменты эпохи персонализированной медицины.
Существует прямая логическая и математическая связь с тем, что по мере роста объема данных о пациентах и научных данных компьютеризированные системы поддержки принятия врачебных решений увеличивают потенциал точности диагностики и становятся все более совершенными и надежными инструментами для практикующих врачей.
Однако внедрение СППВР в клиническую помощь порождает ряд предсказуемых правовых проблем для поставщиков медицинских услуг и разработчиков систем искусственного интеллекта в России и во всем мире. Уже приняты первые регулирующие документы, но законодательство в этой сфере еще находится на стадии становления и совершенствования. Трудности связаны с решением ряда вопросов. Как использование машинных алгоритмов связано с профессиональными стандартами медицинской диагностики для обеспечения гарантированного качества врачебных услуг? Как должно быть организовано тестирование, прежде чем СППВР можно будет использовать в обычной практике? Каковы потенциальные обязательства поставщиков медицинских услуг и разработчиков систем ИИ, если СППВР не работает должным образом? Как юридические требования по защите данных пациентов и общие права на неприкосновенность частной жизни применяются к вероятным сценариям работы системы?

Первопроходцем сквозь юридические дебри в России стала компания «K-SkAI», впервые зарегистрировавшая в нашей стране СППВР Webiomed, как медицинское изделие. О том, как проходила регистрация клинической цифровой системы поддержки принятия решений рассказывает директор по развитию проекта Александр Владимирович Гусев.
- Начать хотелось бы с описание системы Webiomed. Как давно она разрабатывается и с какой целью была создана?
- Webiomed — это одна из разновидностей систем поддержки принятия клинических решений с использование искусственного интеллекта для выявления пациентов с повышенным риском и прогнозирования заболеваний. Основная задача системы — помочь врачам и организаторам здравоохранения своевременно определять и предупреждать развитие возможных заболеваний. Нейронными сетями обрабатываются обезличенные данные о состоянии здоровья пациентов и, используя различные методы анализа, которые позволяют выявить факторы риска и обеспечить раннюю диагностику различных заболеваний, чтобы определить группу риска на их основе.
Система Webiomed является неотъемлемым компонентом цифрового здравоохранения в нашей стране, направленного на создание инновационных цифровых технологий, способствующих снижению смертности и медицинских ошибок, повышению эффективности защиты и сохранения здоровья наших соотечественников.
Программное обеспечение предиктивной аналитики Webiomed не только формирует витальные показания и прогнозы с комплексной оценкой вероятности развития заболевания, но предлагает врачу и пациенту персональные рекомендации, касающиеся тактики обследования и лечения.

- Как работает система?
- Это — облачный сервис, он встраивается в любые медицинские информационные системы и любые программные продукты. На вход Webiomed принимает обезличенную медицинскую информацию, данные о врачебных осмотрах, инструментальных и лабораторных исследованиях, анализируют эту информацию различными способами, и находит либо подозрение на какое-то заболевание, которое, возможно, в данный момент развивается, либо находит предикторы будущей болезни, и через них выстраивает прогноз вероятности ухудшения этого заболевания, его развития.
Особенность этого проекта состоит в том, что мы стараемся для поставленной задачи комбинировать разные способы: там где, это можно решить простыми надежными подходами, мы применяем простые алгоритмы. Но задача предикции — это выявление персональных генетических и приобретенных предрасположенностей пациента, и это довольно сложно, так как нужно учитывать и сопоставлять огромный массив вводной информации. Решается эта задача непросто с точки зрения математики и предметной области задача, поэтому машинное обучение, как способ создания предсказательного алгоритма, является базовым и основным. Упор мы в своем проекте делаем именно на это.
- Какие клинические исследования проводились Вами в процессе подготовки к регистрации системы?
- Компанией ООО «К-Скай» было проведено большое исследование, посвященное перспективам использования искусственного интеллекта для прогнозирования сердечно-сосудистых заболеваний.
Тема для изучения была выбрана потому, что риски заболеваемости и смертности, связанные с сердечно-сосудистыми заболеваниями, сохраняют печальное лидерство в нашей стране и во всем мире уже не первый десяток лет. Главными инструментами борьбы с заболеванием считаются первичная профилактика, основанная на своевременном выявлении и управлении факторами, увеличивающими вероятность развития данного заболевания.
Профилактическая медицина для управления рисками ССЗ использует специальные шкалы, которые стали итогом длительных проспективных клинических исследований. Иногда их еще называют рискометрами. Однако точность прогнозирования с применением разработанных шкал, как показывает практика, имеет существенные ограничения. Мы постарались их преодолеть с помощью машинного обучения, используя нелинейные взаимосвязи и более глубокую настройку между факторами риска и результатами заболеваний.
Для обучения ИИ мы взяли данные о состоянии здоровья более двух тысяч пациентов и обучили модель по признакам, применяющимся для построения фрамингемской шкалы, а затем провели сравнение полученной модели и фрамингемской шкалы по точности прогнозов появлении ССЗ. Результат использования алгоритмов машинного обучения, включая алгоритмы глубокого обучения для прогнозирования рисков ССЗ, показал повышение точности почти на девять процентов. Качество прогноза тоже стало выше.

- Как формировались исходные данные?
- Мы включили в базу данных исследования пациентов, среди которых были как люди, имеющие хронические сердечно-сосудистые заболевания, так и те, кому такой диагноз не был поставлен. В обучаемой модели прогнозирования мы учитывали такие основные базовые переменные как возраст, пол, показания систолического и диастолического артериального давления, образ жизни, вредные привычки, анализ крови, наличие сопутствующих хронических заболеваний, прием антигипертензивных препаратов и т.п. В качестве методов машинного обучения использовалась модель искусственной нейронной сети с двумя скрытыми слоями. В настоящее время мы существенно расширяем как число пациентов, так и число признаков, характеризующих здоровье – чтобы вести дальнейшее повышение точности наших моделей, а также добавляем новые прогнозы.
- Как проходил процесс регистрации?
- Работа системы построена на собственной комплексной методике определения рисков развития заболеваний и их осложнений, включающей применение моделей машинного обучения и нескольких вспомогательных алгоритмов на базе клинических рекомендаций и шкал оценки рисков.
Для нас, конечно, определенной и достаточно сложной вехой стало обоснование ответа на вопрос о том, является ли медицинским изделием тот программный продукт, который мы делаем. Непосредственно всю процедуру, связанную с подготовкой регистрации, мы начали достаточно давно. Большую помощь нам оказало участие в рабочей группе при Росздравнадзоре по проблематике регистрации программного обеспечения как медицинского изделия, в которую мы вошли как члены ассоциации разработчиков и пользователей искусственного интеллекта «Национальная база медицинских знаний».
У нас стране есть четыре четких внятных критерия, согласно которым практически любая система поддержки принятия врачебных решений — это медицинское изделие.
Согласно действующего Федерального Закона в настоящее время запрещен оборот незарегистрированных программных продуктов, которые подпадают под критерии медицинского изделия.
Главной отправной точкой для нас стало то, что наша разработка — это инвестиционный проект, по сути стартап, и в первую очередь, кроме научного подтверждения, нам была важна проверка бизнес-гипотезы, подтверждение, что разработка, которую мы ведем, востребована врачами и организаторами здравоохранения. И для того, чтобы в рамках закона осуществлять продажи, мы изначально ставили себе задачу получить регистрацию. Конечно, это существенный риск для проекта, и мы должны были этот риск рано или поздно устранить.
В нашей стране нормативные требования по регистрации прописаны достаточно четко. Они включают несколько этапов, и эти этапы, их последовательности, сложность зависят от класса риска, то есть от той потенциальной угрозы, которую программный продукт приносит.
Наша система по критериям, по совокупности своих характеристик подпадала под первый класс потенциального риска, и для того, чтобы пройти государственную регистрацию, нам нужно было сделать 4 таких в целом, как бы понятных вроде, как шага.
- Но «дьявол в деталях»?
- Верно! Нам необходимо было пройти, в первую очередь, технические испытания, получить положительное решение.
Мы пошли на клинические испытания, в результате которых был подготовлен комплект документов. Этот комплект документов был в установленном законом порядке направлен в Росздравнадзор, который, в свою очередь, по предусмотренной процедуре направил его на экспертизу в соответствующую организацию.
Экспертиза была достаточно предметной. Мы непосредственно уже прошли процедуру государственной регистрации, которая оказалась для нас как раз самым понятным, самым простым процессом.

На слайде показано, что анализировалось экспертами в программном продукте и, после того как было получено положительное заключение об успешно пройденной экспертизе.
- Был ли у Вас ранее опыт регистрации медицинских изделий?
- Да! Наша команда уже имела и опыт клинических испытаний регистрации другого нашего программного обеспечения: лабораторной информационной системы. Поэтому мы достаточно неплохо, на мой взгляд, в целом этот процесс понимали и, тем не менее, когда мы стали регистрировать систему искусственного интеллекта – то встретили очень много всяких подводных камней, барьеров, которые мы преодолевали.
- С какими сложностями Вы столкнулись?
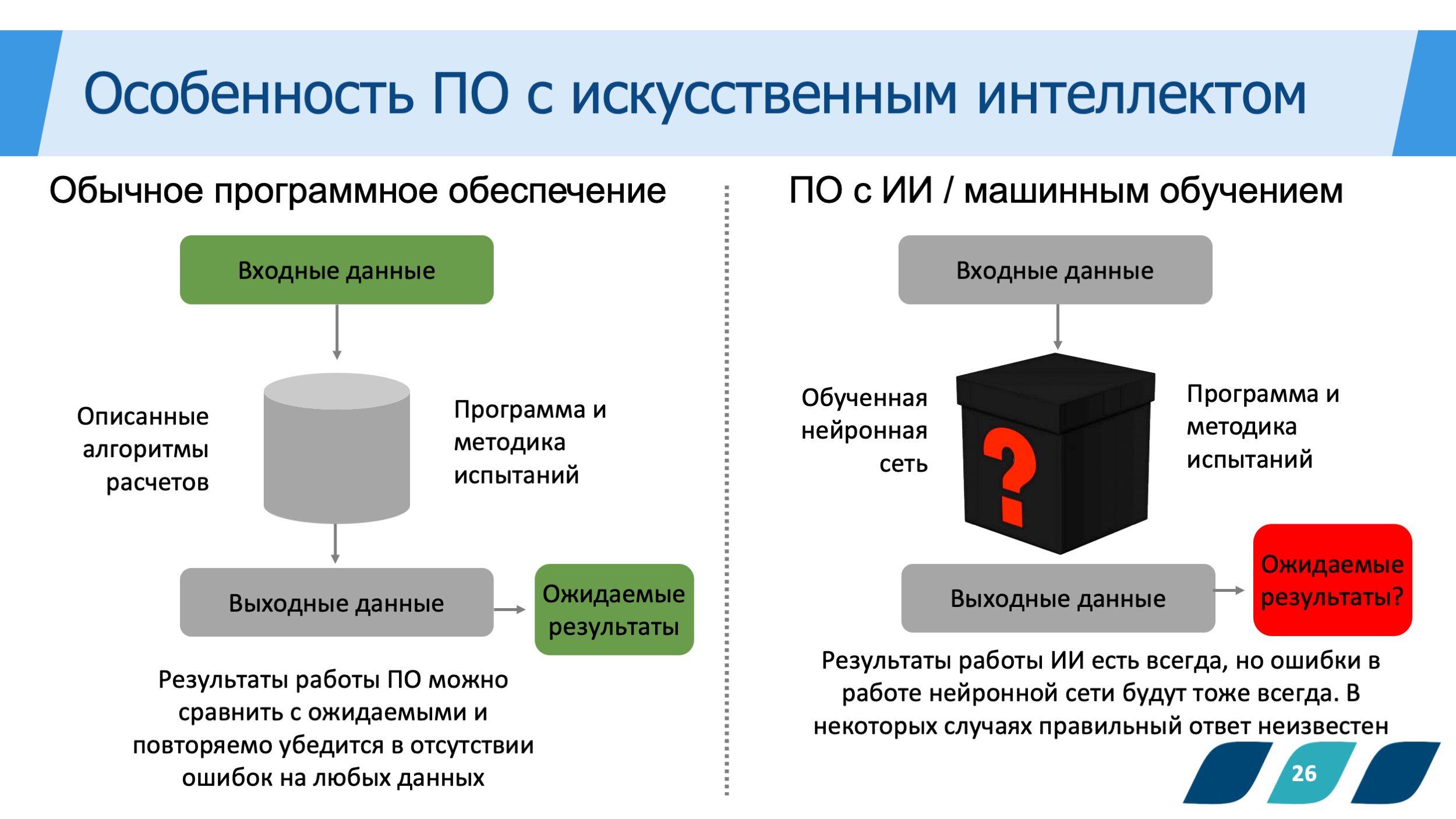
- Все это, так или иначе, с особенностями самого цифрового продукта —применение в работе программы алгоритмов, моделей, которые создаются с машинным обучением.
Вот вся необычность и вся внутренняя природа такого программного обеспечения настолько радикально отличается от обычной программы, которая построена на известных знаниях, известных алгоритмах, что именно это определило всю сложность.
Вторая проблема, с которой мы столкнулись, оказалась неожиданной, хотя теперь мы понимаем, что мы изначально должны были быть к ней готовы. Так как мы создаем, по сути, модель, которая выводит врачу подсказку, что может быть с пациентом в ближайшее время, то не все подсказки однозначны. Только некоторые из них достаточно четкие, мы прямо говорим, какое заболевание, либо какое событие, с ним связанное, может произойти в ближайшие там год, три, пять лет и так далее.
Во время разработки дизайна клинического испытания мы столкнулись тем, что когда наш алгоритм отработал и сделал подсказку врачу «обратите внимание: у этого пациента может развиться заболевание», но это событие в течение какого-то времени еще не наступило.
И возникает вопрос, сколько нужно ждать, чтобы проверить правильность алгоритма? Так получилось, что мы в основном упор делали на сердечно-сосудистые заболевания, и их манифест может наступить через много-много лет. Соответственно ждать пять- десять лет, пока будет проверен алгоритм, невозможно, потому что за это время никакого финансирования, никаких сил не хватит. Нам, как стартапу, было очень важно все проверить за короткое время.
Следующий момент, который тоже требовал решения. А если тот прогноз, который СППВР дала, не сработал, является ли это ошибкой СППВР? Или, наоборот, так как он вовремя подсказал, врач смог подобрать какие-то предиктивные меры, то предсказанное заболевание было отсрочено, не наступило, либо прошло не в такой яркой форме, как мы предсказывали? И это несовпадение является не ошибкой программы, а, наоборот, целью ее разработки.
Эксперты — те, кто нас консультировал и внешняя организация, которая проверяла, эти вопросы нам задавали.
- Поделитесь опытом, как Вам удалось решить все эти проблемы?
- Во-первых, для модели, для искусственного интеллекта, который предсказывает события, на данный момент времени мы нашли выход в виде ретроспективного дизайна клинического испытания, потому что проспективный метод, в общем-то, для наших экспертов был желанным, но, с точки зрения стартапа, он был неприемлем.
Мы смогли найти ответ на вопрос: как надёжно проверить алгоритмы?!
Мы считаем, что все испытания должны проходить только во внешней, никак не связанной с нами организации, которая сама должна привлекать партнеров для отбора данных. Обязательно, если есть алгоритмы, построенные на нейронных сетях, или всё, что связано с Blackbox — это должны быть независимые наборы данных, не те данные, на которых производилось обучение.
И очень важно собрать доказательную базу на данных, которые были бы не характерны только для одной медицинской организации или для одного города. Наши консультанты, те, которые имели опыт по клиническим испытаниям, настоятельно рекомендовали, чтобы дизайн подразумевал сбор данных от очень разных регионов, очень разных медицинских организаций, чтобы попытаться найти все ошибки, которые могут влиять на алгоритм, например, с точки зрения особенности пациента, особенностей ведения данных и так далее.
- И как в итоге все это отразилось на ИИ?
- У нас есть несколько моделей в продукте, и каждая модель была четко описана. Мы говорили, что именно прогнозирует модель, мы описывали входные и выходные данные, примененные методы машинного обучения, измеряли стандартные метрики, и нам очень важно было доказать свою клиническую эффективность через сравнение с аналогами.
Мы проводили испытания не на людях. Мы проводили ретроспективный метод через сравнение с аналогами.
На слайде показано, как сравнивалась точность прогнозирования с помощью Фрамингемской шкалы.
- Кто вам помогал в процессе разработки и регистрации?
- Очень важной и огромной помощью стало партнерство. Только сотрудничество с научными ассоциациями, подключение профильных носителей знаний, помогли нам учесть все тонкости, обогнуть все эти подводные камни, с которыми мы столкнулись. В одиночку мы бы с ними не справились. Мой совет коллегам: не сидеть внутри своего замкнутого пространства, внутри своей команды, а сотрудничать.
И также нам огромную помощь оказали методические документы. Их очень мало в нашей стране: какой дизайн того или иного этапа, какие метрики, какой подход должен быть к продукту, его испытаниям, чтобы потом, когда время на всю эту работу было потрачено, результаты этих испытаний были бы признаны экспертами, и они бы доверяли этим данным.
Сейчас нас на руках положительное экспертное заключение, Росздравнадзор зарегистрировал наш программный продукт. Мы получили регистрационное удостоверение, и готовимся к следующему этапу, к работе.

- По поводу вашего открытия доступа к системе оценки тяжести пневмонии. Как удалось столь быстро отреагировать на всем известные события?
- Тут, честно говоря, просто повезло. В тот перечень функций, который был включен в первую версию, которая обкатывалась в наших пилотных проектах, включалось несколько алгоритмов определения тяжести течения внебольничной пневмонии.
То есть сценарий применения этих алгоритмов простой: когда пациент поступает с подозрением либо с предварительным диагнозом пневмония в стационар, очень важно оценить тяжесть этого заболевания, чтобы правильно принимать решение о маршрутизации, как следует этого пациента лечить. Это много вопросов по тактике, и эти вопросы, в том числе, оцениваются на тяжести.
И когда началась пандемия, мы увидели, что этот алгоритм может пусть маленький, но вклад в общую борьбу внести и наши инвесторы приняли решение открыть доступ к платформе, и сейчас любой желающий, кому интересны алгоритмы, могут бесплатно подключаться платформе, мы даем всю документацию и техническую поддержку.
- Можете сказать, сколько времени занял у вас процесс регистрации? Какой путь по времени для вас является оптимальным?
- Сам процесс регистрации как финальный этап был очень быстрый, никаких задержек. Не скрою при этом, что мы все-таки допустили некоторые ошибки в ряде документов, но мы достаточно быстро из Росздравнадзора, от экспертов получили внятные и четкие замечания. Мы их устранили за 10-20 дней и заново подали документы на регистрацию. Основное время ушло не на регистрацию, а на подготовку и на испытания.
Я глубоко уверен, что с точки зрения процедуры государственной регистрации, по большому счету, нечего ускорять: тут все четко и прозрачно. Упрощать и укорять необходимо именно подготовительный этап и процедуры испытаний продуктов, т.к. они предшествуют регистрации и как раз занимают львиную долю времени.
Мы несколько месяцев потратили на поиск медицинской организации, которая, с одной стороны бы имела авторитет и уровень, приемлемый в глазах экспертов, но, с другой стороны, содержала бы внутри себя специалистов, которые могли бы испытывать не просто программное обеспечение, а программное обеспечение с применением элементов искусственного интеллекта.
Инвесторам и стартапу надо проходить испытания, в этом нет сомнений, но срок, приемлемый по деньгам и по рискам — в идеале от 3 до 6 месяцев. Он, с одной стороны, давал бы доверие продукту, но, с другой стороны, был бы приемлем по длительности.
Сколько стоила разработка проекта?
Во-первых, у этого процесса есть прямые затраты, потому что и технические испытания, и клинические испытания проводятся, безусловно, внешними организациями, и эта работа делается на коммерческих условиях.
Цены очень разные. Могу сказать, что мы рассматривали предложения от 100 тысяч на один из этапов, до 5 - 6 миллионов.
И очень много было косвенных затрат, потому что нам просто пришлось много ездить, общаться с научными организациями — это все командировочные затраты. Много работы пришлось переделывать, например мы какие-то доработки внутри алгоритмов или внутри продукта делали. Мы видели, что они не проходят по каким-то метрикам, либо, например, не подпадает под дизайн испытания. Это все работа наших программистов, специалистов по данным и машинному обучению, которая, в любом случае, внутри бухгалтерской системы проекта пошла по статье затрат к регистрации.
- Что еще вы хотели бы пожелать коллегам, которые только готовятся к регистрации своих цифровых разработок?
- Один из ярких выводов, в которых мы абсолютно уверены, состоит том, что без стандартизации каждого этапа испытаний очень тяжело нашим коллегам стартапам будет их пройти. Стандартизация — это путь сокращения времени, снижения издержек, облегчения сложностей и повышения прозрачности этой процедуры, а значит и ее прогнозируемости для инвесторов по длительности и затратам.
Перечень стандартов на уровне Российского технического комитета уже принят. Мы очень надеемся, что в этом году ключевые стандарты в нашей стране будут разработаны и утверждены.
Подготовила Надежда Данилова


