Глубокое обучение в радиологии: разговор с дата-саентистом
Care Mentor AI - система искусственного интеллекта для анализа и интерпретации результатов лучевых методов исследования, играющих важную роль в диагностике и лечении различных заболеваний.
Разработка предназначена для самопроверки рентгенологов, для выработки альтернативных заключений и анализа архивных рентгенограмм, а также аудита и научных целей.
В практической реализации система может быть легко освоена врачами: достаточно просто загрузить исследование и оно автоматически будет проанализировано нейросетью, которая интегрирована в рабочее место. Результатом анализа является автоматическое формирование протокола исследования Care Mentor AI и отчеты о случаях расхождения мнений с рентгенологом по критерию «Здоров – Болен».
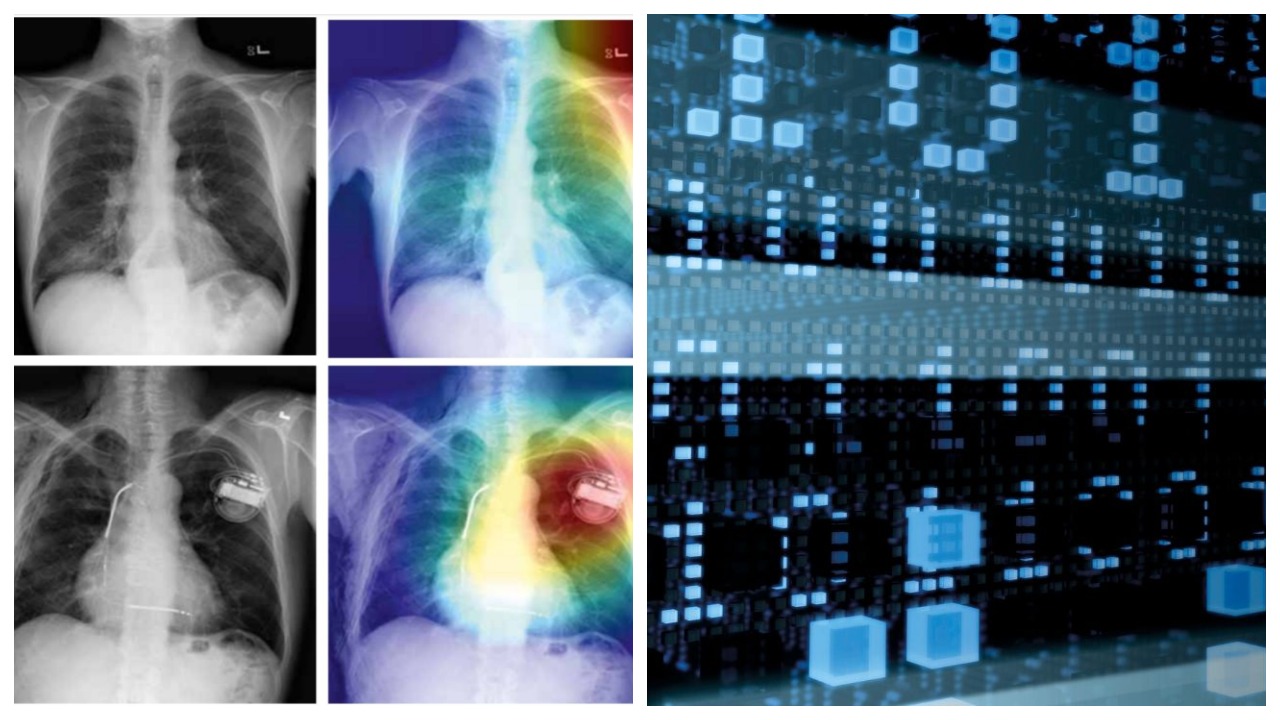 Альтернативный и независимый анализ рентгенограмм востребован в качестве «второе мнения» и медорганизациями, и пациентами, является современным полезным инструментом, как для ассистентов рентгенологов, так и для экспертов.
Альтернативный и независимый анализ рентгенограмм востребован в качестве «второе мнения» и медорганизациями, и пациентами, является современным полезным инструментом, как для ассистентов рентгенологов, так и для экспертов.
Система Care Mentor AI создана на основе глубокого обучения, также известного как иерархическое обучение, являющегося типом машинного обучения, включающего алгоритмы и основанного на представлении данных обучения.
Глубокое обучение давно используется в области медицины, особенно в радиологии. При глубоком обучении машина или компьютер узнают о задачах классификации непосредственно из ввода звука, текста или изображения. Программы, использующие глубокое обучение, могут выполнять задачи точно и часто на более высоком уровне, чем люди.
Глубокое обучение значительно улучшило производительность компьютерных алгоритмов в медицинской практике. Медицинские технологии развивались, чтобы позволить извлекать важную информацию из изображений, которые, возможно, было труднее интерпретировать с использованием традиционных методов.

О том, на каких принципах базируется система Care Mentor AI мы попросили рассказать дата-сайентиста компании Евгения Алексеевича Жукова.
- Среди разработчиков есть некоторое противостояние: машинное обучение против глубокого обучения ИИ. Вы в каком лагере?
- Стоит начать с того, что по факту, глубокое обучение является одним из ответвлений машинного обучения, за тем лишь исключением, что акцент сделан на одном классе математических моделей — нейросети. Тогда как машинное обучение в целом подразумевает работу с более широким классом как линейных, так и нелинейных моделей, деревьями решений, и т.д. Как правило, те, кто занимается глубоким обучением, в достаточной степени подкованы и в машинном обучении в целом.
Но обратное утверждение уже может быть неверным. В нашей области, как и в других сферах, можно быть хорошим специалистом широкого спектра, а можно развиваться, как эксперт в какой-либо конкретной области. В частности — в области глубокого обучения.
Несмотря на то, что процесс обучения нейросетевых моделей для решения задач машинного зрения требует хорошего знания понятий и концепций, являющихся общими для задач машинного и глубокого обучения (например, метрики качества, алгоритмы оптимизации), необходимо быть профессионалом. Для глубокого обучения ИИ важно уметь грамотно использовать ряд специфических классических и современных техник, касающихся обработки изображений, построения архитектур нейросетей, их обучения и т.д.
Отвечая на вопрос, в каком мы лагере? Выходит, что скорее в лагере глубокого обучения. Но в армии машинного обучения.
- Можно ли говорить о единой методологии, схожих инструментах и метриках для создания наборов данных обучения, тестирования и проверки алгоритмов или по каждой конкретной болезни нужно изобретать нечто новое?
- И да, и нет. Я бы сказал, что можно описать унифицированный подход именно к организации рабочего процесса по сбору и подготовки данных, выбору модели, алгоритма её обучения, метрик качества и т. д. Но специфика каждого этапа уже будет напрямую зависеть от решаемой задачи.
Пример таких общих рекомендаций: если решается задача классификации - определение какой-либо патологии или ряда патологий на рентген снимке, то при формировании обучающего набора данных очень желательно, чтобы количество снимков с патологиями было таким же, как и количество снимков без патологий.
Однако на практике такое условие зачастую недостижимо. И в зависимости от того, в каком балансе находятся данные, разрабатывается тот или иной алгоритм обучения, и выбираются метрики качества.
Поэтому рабочий процесс специалиста по машинному/глубокому обучению будет всегда по большей части состоять из цикла одних и тех же этапов, включая понимание задачи, анализ данных, выбор метрик, построение и оценка модели, но со спецификой каждого этапа, уникальной в рамках решаемого класса задач.

- Существует ли возможность разработать стандартизированные пути внедрения алгоритмов ИИ в клиническую практику?
- Все в первую очередь зависит от конкретной области медицины, где планируется применение ИИ, от степени ответственности, накладываемой на решение, а так же от того, используется ли алгоритм самостоятельно, или как экспертная система - ассистент в помощь врача. Разумеется, что определённая погрешность в определении плоскостопия не будет стоить жизни пациенту, в то время как пропуск моделью крошечного новообразования в мозге может сыграть критическую роль в постановке диагноза.
Таким образом, в настоящий момент, порог входа ИИ в медицину более низкий в одних областях, и более высокий в других. Но, тем не менее, я считаю, что по факту процессы внедрения ИИ от сферы к сфере в большинстве случаев сходны между собой — он, как правило, цикличный и итеративный — где-то просто потребуется большее количество итераций и времени для каждого этапа внедрения.
Так же хочется отметить, что для того, чтобы ИИ без труда внедрялся в клиническую практики, в первую очередь необходимо его обеспечить качественными сбалансированными данными.
Не должно быть расхождений между врачами при разметке данных, сами данные должно быть представлены в достаточном объёме. Так же данные, на которых тестируется алгоритм, должны отражать данные, которые будут использованы уже в «промышленной эксплуатации» модели — для объективной оценки модели. Дайте модели данные — и модель даст вам результат, который отметят врачи, и который не будет противоречить обобщённому мнению нескольких врачей. В таком случае и доверие к модели будет больше, и, соответственно, проще процесс её внедрения.

Подготовила Надежда Данилова

