
ИИ превосходит врачей в составлении медицинских записей
Трудоемким, но важным аспектом медицинской практики является документирование медицинских карт пациентов. Врачи часто тратят значительную часть своего времени на обработку огромного количества текстовых данных, и даже у очень опытных врачей этот процесс сопряжен с возможностью ошибок.
Переход от бумажных записей к электронным медицинским картам только увеличил объем работы по ведению клинической документации, и, по некоторым данным, врачи тратят около двух часов на документирование клинических данных, полученных в результате взаимодействия с одним пациентом. Медсестры тратят около 60 % своего времени на ведение клинической документации, и временные требования этого процесса часто приводят к значительному стрессу и выгоранию.
Хотя большие языковые модели (LLM) представляют собой отличный вариант для обобщения клинических данных, их эффективность и точность при обобщении клинических данных не подвергались широкой оценке.
В недавнем исследовании, опубликованном в журнале Nature Medicine, международная команда ученых определила лучшие LLM-системы и методы для клинического обобщения больших объемов данных электронных медицинских карт и сравнила эффективность этих моделей с результатами работы медицинских специалистов.
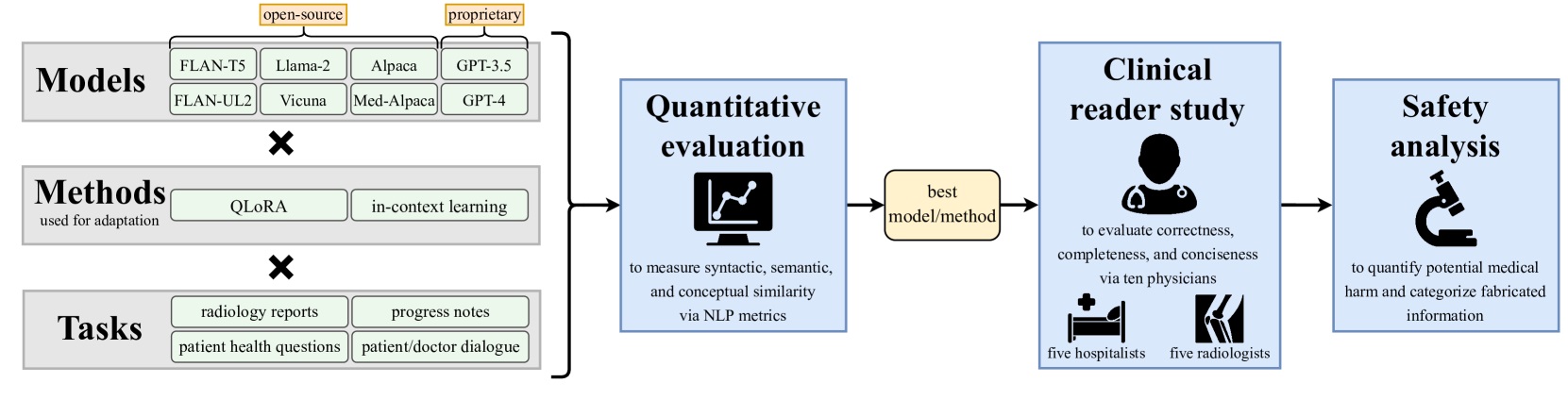
В этом исследовании ученые оценили восемь LLM в четырех задачах обобщения клинической информации: вопросы пациента, рентгенологические отчеты, диалог между врачом и пациентом и записи о проделанной работе.
Сначала они использовали количественные показатели обработки естественного языка, чтобы определить, какая модель и метод адаптации показали наилучшие результаты в четырех задачах обобщения. Затем десять врачей провели исследование, в ходе которого они сравнили лучшие резюме, полученные с помощью LLM, с резюме, полученными от медицинских специалистов, по таким параметрам, как краткость, корректность и полнота.
Наконец, ученые оценили аспекты безопасности, чтобы определить проблемы, такие как искажение информации и возможность нанесения медицинского вреда при обобщении клинических данных медицинскими экспертами и LLM.
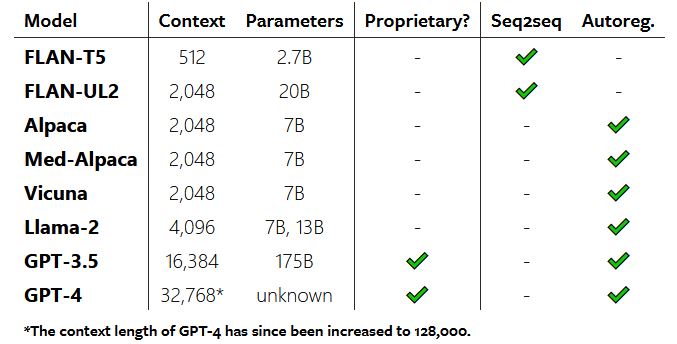
Для оценки восьми больших языковых моделей использовались два широких подхода к генерации языка — авторегрессионные и seq2seq-модели.
Четыре области задач, использованных для оценки LLM, включали в себя:
- обобщение радиологических отчетов с использованием подробных данных о радиологических анализах и результатах;
- обобщение вопросов пациентов в виде сжатых запросов;
- использование записей о ходе лечения для составления списка медицинских проблем и диагнозов, а также
- обобщение взаимодействия между врачом и пациентом в виде параграфа об оценке и плане.
Результаты показали, что 45% резюме, составленных с помощью наиболее адаптированных LLM, были эквивалентны резюме, составленным медицинскими специалистами, и 36% превосходили их. Более того, в исследовании резюме на основе LLM оказались лучше, чем резюме медицинских экспертов, по всем трем параметрам: краткость, правильность и полнота.
Кроме того, ученые обнаружили, что "инженерия подсказок", т. е. процесс настройки или модификации входных подсказок, значительно улучшил производительность модели. Это было особенно заметно по параметру краткости, когда конкретные подсказки, предписывающие модели обобщать вопросы пациентов в запросы с определенным количеством слов, помогали значимо сократить информацию.
Отчеты по радиологии были единственным аспектом, где краткость резюме у LLM была ниже, чем у медицинских экспертов, и ученые предположили, что это может быть связано с нечеткостью входных подсказок, поскольку в подсказках для краткого изложения отчетов по радиологии не было указано ограничение на количество слов. Однако они также считают, что проверка с помощью других LLM-систем или нескольких моделей, а также с помощью человека может значительно повысить точность этого процесса.
В целом исследование показало, что использование LLM для обобщения данных в медицинских картах пациентов работает так же хорошо или лучше, чем обобщение данных медицинскими специалистами. Большинство этих LLM-систем получили более высокие баллы, чем человеческие операторы, в метриках обработки естественного языка, кратко, правильно и полно обобщая данные.



